NỘI DUNG
Kết thúc nội dung Bash Script – Đánh tan lờ đờ, mệt mỏi của repetitive tasks với Loops và Function, tôi có hứa hẹn sẽ kiếm cái demo nào có nội dung gay cấn tí minh họa. Và cũng như mấy lần trước, tôi lại phải dựa hơi ông Offensive Security để phần demo thêm phần sinh động. Theo đó, mục tiêu của phần demo như sau: Tìm tất cả subdomains được liệt kê trong trang chủ của megacorpone.com và tìm các địa chỉ IP tương ứng.
Để mần được việc này, bạn có thể có nhiều phương án xử lý. Tuy nhiên, để liền mạch với các nội dung đã giới thiệu, phần demo sau đây sẽ ưu tiên xử lý với các người quen grep/awk/cut, Regular Expression và For loop trong Bash Script.
#1 Xử lý dữ liệu với các combo grep/awk/cut
#1.1 Download dữ liệu
Trước khi có thể xử lý, hiển nhiên bạn phải có dữ liệu cái đã. Để lấy dữ liệu, bạn có thể download trang index.html của mục tiêu www.megacorpone.com với wget như sau:
wget www.megacorpone.com

Lưu ý: Nếu chưa biết gì về việc download, bạn có thể xem thêm nội dung Giải ngố Kali Linux – Phần 8: Download file trên Linux với wget và curl.
Sau khi hốt hàng về, bạn có thể kiểm tra thử nội dung index.html với:
cat index.html
#1.2 Mông má dữ liệu đầu ra với grep/awk/cut
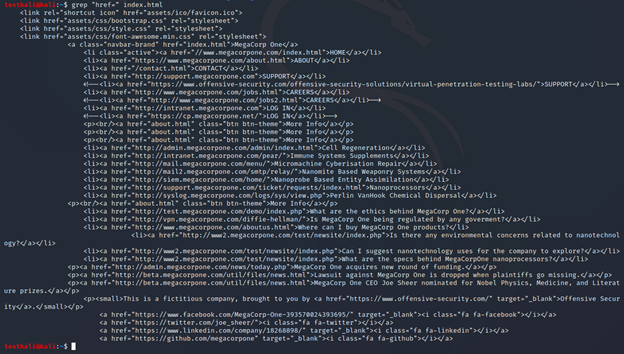
Như bạn thấy, nội dung của file index.html khá dài và khó đọc. Nếu bạn đang rảnh không có việc gì làm thì có thể soi từng dòng để tìm đám subdomains. Hoặc dùng một lựa chọn ít “khổ d*m” hơn là lọc tìm HTML links trong index.html với grep “href=” như sau:
grep "href=" index.html
Lưu ý: Vấn đề sử dụng grep tôi có đề cập trong nội dung Giải ngố Kali Linux – Phần 5: Nâng cấp kỹ năng tìm kiếm trên Linux với grep command
Bệnh tình đã có chuyển biến tích cực nhưng bạn có thể làm khá hơn bằng cách lọc tiếp chỉ các dòng chứa “.megacorpone” (nghĩa là các dòng có liên quan đến subdomain của megacorpone.com) cũng như loại bỏ luôn những dòng chỉ chứa đúng domain www.megacorpone.com với grep -v.
grep "href=" index.html | grep "\.megacorpone" | grep -v "www\.megacorpone\.com" | head

Lưu ý: Phần liên quan đến head tôi có giới thiệu trong nội dung Giải ngố Kali Linux – Phần 7: Nâng cấp kỹ năng giám sát hệ thống và file với tail command.
Hàng họ đã ngon mắt hơn rồi nhưng bạn cần tiếp tục dọn dẹp để tập trung vô đám subdomains. Ở đây, như tôi nói, có thể có nhiều giải pháp, tuy nhiên bạn có thể tiếp tục với option -F của awk như tôi giới thiệu trong nội dung Giải ngố Kali Linux – Phần 5: Nâng cấp kỹ năng tìm kiếm trên Linux với grep command. Với option -F của awk, bạn có thể thiết lập delimiter là “http://” để cắt các dòng thông tin thành 2 phần và hốt hết đám sau delimiter với ‘{print $2}’.
grep "href=" index.html | grep "\.megacorpone" | grep -v "www\.megacorpone\.com" | awk -F "http://" '{print $2}'

Dễ thấy (cái này dễ thấy thật, không phải kiểu “dễ” mà tôi hay ti toe trong các nội dung khác), đám subdomains sẽ đứng trước cái “/” đầu tiên từ trái sang. Như vậy bạn có thể dùng cut như tôi giới thiệu ở nội dung Giải ngố Kali Linux – Phần 5: Nâng cấp kỹ năng tìm kiếm trên Linux với grep command. Delimiter được sử dụng tương ứng sẽ là “/” với option -d sau đó hốt cái field đầu tiên với option “-f 1”.
grep "href=" index.html | grep "\.megacorpone" | grep -v "www\.megacorpone\.com" | awk -F "http://" '{print $2}' | cut -d "/" -f 1
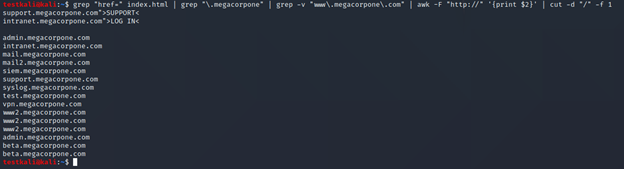
Ngon! Giờ chỉ cần lọc đám subdomain bị trùng thì hàng chuẩn cmnr!
Nhưng (Mịa! Lúc nào cũng có chữ “nhưng”), nếu lỡ đụng mấy dòng không có đồng thời “http://” và “href=” thì sao? Nếu không chấp nhận bỏ sót thì bạn phải xử lý các tình huống đẻ nhánh hoặc thậm chí quay về con đường “khổ d*m” dò bằng mắt từ đầu đến đít à?
#3 Regular Expression to the Rescue
#3.1 Lợi thế đến bất công với Regular Expression
Rất may mắn, bạn vẫn còn một chiêu để diệt trùm cuối là Regular Expression để hốt hết đám “.megacorpone.com” subdomains một cách đơn sơ và mộc mạc như sau:
grep -o '[^/]*\.megacorpone\.com' index.html | sort -u > list.txt
Sau đó kiểm tra với:
cat list.txt
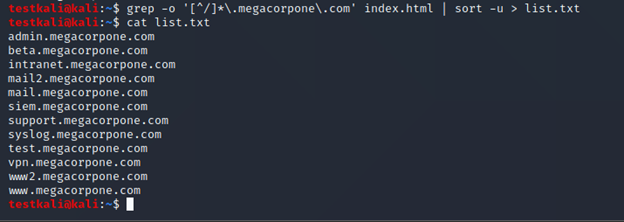
Vâng, “bất ngờ ngỡ ngàng ngơ ngác và bật ngửa”! “Cái “đinh công mạnh” thằng chủ thớt! Trả lại bố 5 phút cuộc đời đã phung phí để đọc đám tào lao xịt bụp từ đầu đến giờ thay vì xử ngay với cái dòng Regular Expression ở trên”.
Dù quan điểm gạch đá nói trên là có cơ sở nhưng tôi nghĩ việc “cày” với đám command grep/awk/cut sẽ giúp bạn thấm thía được cái giá trị của Regular Expression. Ngoài ra, thực tế yêu cầu của bạn đôi khi có thể là tóm một đối tượng nào đó nằm trong nội dung file index.html chứ không chỉ là hốt hết đám subdomains. Khi đó, việc thông thạo các chiêu trò xào chẻ với grep/awk/cut sẽ có thể giúp bạn sáng tác ra được các đòn thế chuẩn xác phù hợp với tình hình hơn.
#3.2 Sức mạnh của Regular Expression đến từ đâu?
Rồi, tôi quay lại vấn đề chính để phân tích xem cái gì mang lại sức mạnh cho command với Regular Expression nói trên:
- grep với option -o: Chỉ trả về các chuỗi xác định trong Regular Expression;
- ‘[^/]*\.megacorpone\.com’, như đề cập trong nội dung Bash Script – La liếm với bộ 3 Variable, Argument & User Input, sẽ bảo đảm các ký tự bên trong single quotes chỉ đơn thuần là ký tự;
- [^/]* là một dạng của negated list (thể hiện qua dấu caret “^” sau opening square bracket “[”) với ý nghĩa nó sẽ tìm một số lượng ký tự bất kỳ (thể hiện qua dấu “*”) nhưng không bao gồm ký tự forward-slash “/”. Bạn có thể thêm các ký tự khác vào negated list bằng cách phân cách nó với dấu phẩy “,” (ví dụ [^/,”]* sẽ loại bỏ cả forward-slash và and double-quote;
- Dấu chấm “.” sẽ được escaped với backslash theo kiểu “\.” (xuất hiện 2 lần trước megacorpone và com) để loại trừ các tác dụng khác và chỉ xem xét nó đơn thuần là 1 ký tự “.” nhằm đảm bảo string mà grep hốt về phải kết thúc với “.megacorpone.com”;
- Sau phần hại não Regular Expression nói trên, bạn sẽ lùa đống kết quả (nhờ piping “|”) qua thằng sort để mông má lại cho đẹp trước khi redirect dữ liệu vô file txt.
Lưu ý:
- Phần sort tôi có đề cập trong nội dung Giải ngố Kali Linux – Phần 7: Nâng cấp kỹ năng giám sát hệ thống và file với tail command;
- Phần redirect tôi có đề cập trong nội dung Giải ngố Kali Linux – Phần 5: Nâng cấp kỹ năng tìm kiếm trên Linux với grep command.
Như bạn thấy đấy, đoạn ở trên chỉ mới “phần nổi của tảng băng chìm Regular Expression”. Nếu muốn đào thêm một tí xuống phần “chìm” thì có thể coi thêm cái Quick Reference của ông Microsoft ở Regular Expression Language – Quick Reference | Microsoft Docs.
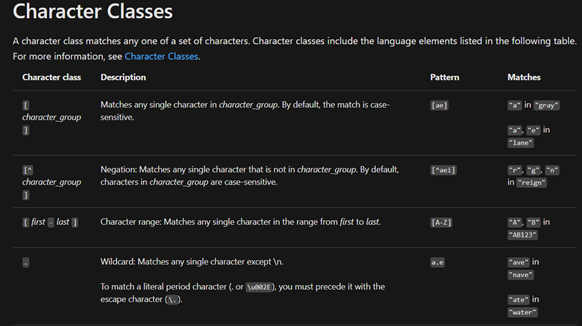
Hoặc đào sâu hơn nữa với nội dung ở trang Regular-Expressions.info – Regex Tutorial, Examples and Reference – Regexp Patterns.
#4 Phân giải domain name với host command và For loop trong Bash Script
Kết thúc phần trên thì bạn đã tìm được tất cả subdomains trong trang chủ của megacorpone.com. Như vậy còn một nhiệm vụ nữa là xác định địa chỉ IP tương ứng cho các subdomains này.
Công việc này có thể được xử lý với host command trên Linux phục vụ các tác vụ Domain Name System – DNS lookup (hay nói đơn giản là tìm địa chỉ IP theo domain name và ngược lại).
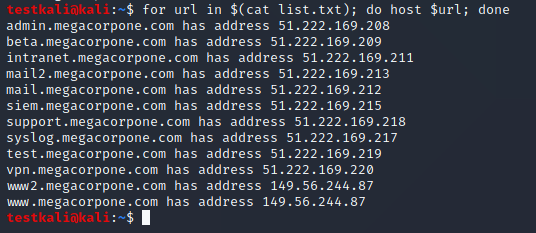
Với kết quả danh sách subdomains đã ghi nhận trong file list.txt, bạn có thể dùng host với for loop dạng Bash one-liner nhanh gọn như sau:
for url in $(cat list.txt); do host $url; done
Lưu ý: Nếu chưa biết gì về Loop trong Bash Script thì bạn có thể xem thêm ở nội dung Bash Script – Đánh tan lờ đờ, mệt mỏi của repetitive tasks với Loops và Function
Kết quả host trả về rất lịch sự nhưng hơi dài dòng. Nếu bạn thuộc thể loại xôi thịt muốn bay vào là múc ngay IP address thì có thể xử lý lại kết quả với grep, cut và sort (Còn nhớ khi tôi nói “việc thông thạo các chiêu trò xào chẻ với grep/awk/cut sẽ có thể giúp bạn sáng tác ra được các đòn thế chuẩn xác phù hợp với tình hình hơn” không? Đây là một trong những “tình hình” như vậy đấy!).
for url in $(cat list.txt); do host $url; done | grep "has address" | cut -d " " -f 4 | sort -u

P/S: Nếu vì một lí do nào đó bạn vẫn chưa rõ đoạn “| grep “has address” | cut -d ” ” -f 4 | sort -u”, vui lòng de lại đọc Mục 1 nhé.
Và đến đây tôi cũng xin phép kết thúc nội dung demo tìm và “diệt” các subdomains của một website target.
1 thought on “Bash Script – Demo tìm và “diệt” Subdomains với các combo grep/awk/cut, Regular Expression và For loop”